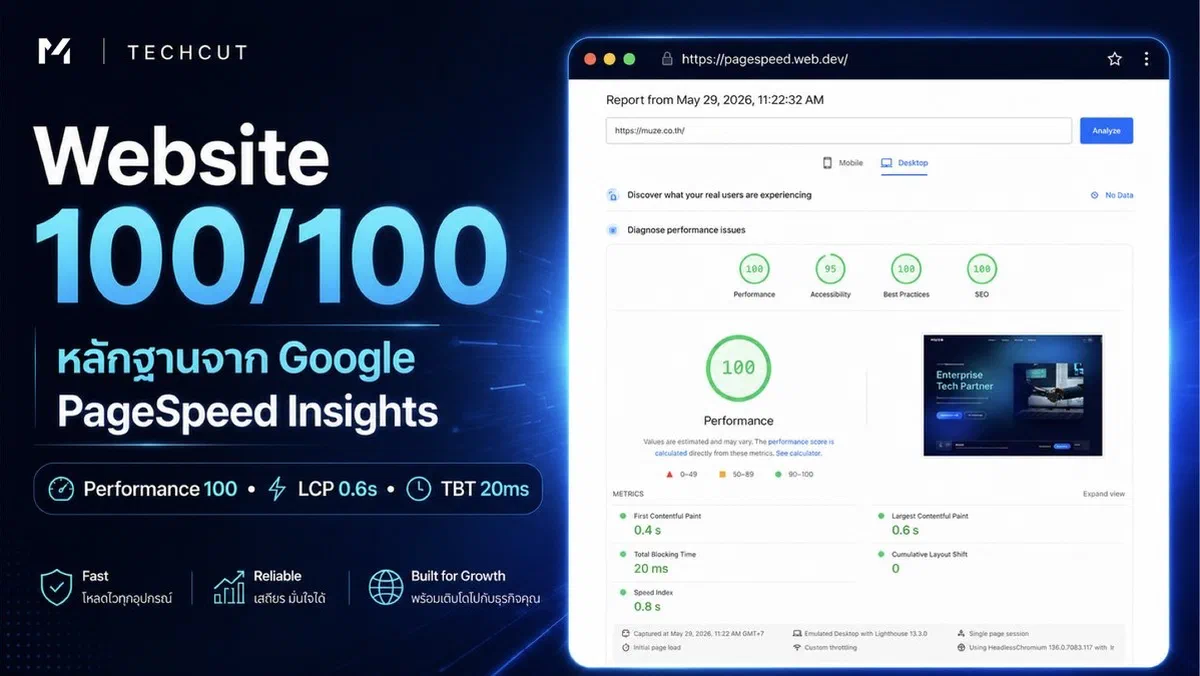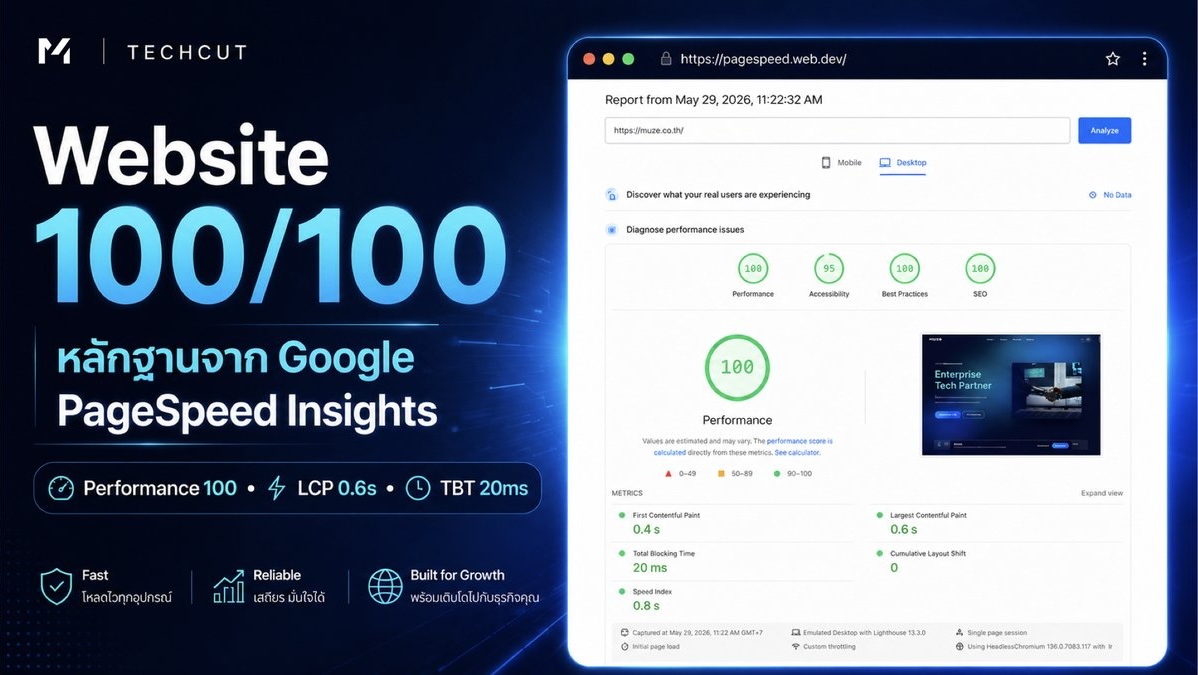
Performance 100. Accessibility 95. Best Practices 100. SEO 100.
This is the PageSpeed Insights result for muze.co.th on production — 29 May 2026.
And this entire website was built with Claude Code — no developer writing code by hand.
But this isn’t a story about hitting a few prompts and getting a perfect result.
Behind the score of 100 is something most “vibe coding” content doesn’t talk about: a measurement framework, iterative fine-tuning, and human judgment applied at exactly the right moments.
1. Define KPIs First — Before Any Prompt
The first step before building anything is answering: what does “done” look like?
For muze.co.th, we set KPIs at three levels:
Performance KPIs
- Lighthouse Desktop: 90+ (achieved 100)
- LCP ≤ 1.2s (achieved 0.6s)
- CLS = 0 (achieved 0)
- TBT ≤ 50ms (achieved 20ms)
AI Search KPIs
- Discoverable from 10+ real buyer queries that potential clients actually use
- Structured data that AI parsers can read to understand what Muze does
Content KPIs
- TechCut scoring ≥ 8.0 before publishing
- Every article must answer “who would search for this, and with what query?”
With clear KPIs, Claude Code knows what to build — and we know what to measure.
2. The Right Architecture From Day One — Hugo Static Site
Before fine-tuning any metric, you need the right architecture first.
We chose Hugo because:
- Generates static HTML — no JavaScript hydration overhead
- muze.co.th page weight: 66 KB vs competitors using WordPress/Wix: 174–1,610 KB
- Hugo handles multilingual (TH/EN) natively with a built-in i18n system — no extra JS needed
Claude Code built the directory structure, layouts, partials, shortcodes, i18n files, and all content organisation. But choosing Hugo was a human decision made before any prompting began.
3. LCP Engineering — Not Just “Make It Look Nice”
LCP (Largest Contentful Paint) measures how quickly the largest visible element loads. For muze.co.th, that’s the hero image.
Getting to LCP 0.6s required multiple iterations:
Round 1: Used <picture><source> + srcset — but browsers may discover the image late because they need to parse HTML first
Round 2: Added <link rel="preload"> for the hero image — but the DPR (device pixel ratio) didn’t match the actual srcset, so the preload didn’t resolve correctly
Round 3: Fixed the preload to specify imagesrcset and imagesizes matching the real media queries — LCP dropped noticeably
Round 4 (reverted): Tried switching from <picture> to <img srcset> for faster browser discovery — LCP didn’t improve, reverted
In each iteration, Claude Code wrote the code. Deciding which approach to try and when to revert was human judgment.
4. Mobile Performance — A Different Problem from Desktop
Desktop 100 doesn’t automatically mean Mobile 100.
Additional work needed for mobile:
Fonts: Changed from synchronous loading to async — added font-display: swap and <link rel="preload" as="font">
Animations: Heavy animations cause scroll jank on mobile — added logic to detect prefers-reduced-motion and skip animations on touch devices
Orb blur: Background blur effects that look beautiful on desktop become a problem on mobile because backdrop-filter: blur() cost scales by radius² on older GPUs — reducing blur from 80px → 30px helps on newer iPhones, but on A11/A12 chips there’s still impact. The right approach is @media (hover: none) to disable blur entirely on touch devices
5. SEO Structured Data — What Competitors Don’t Have
When we audited muze.co.th against other Thai enterprise software companies, Muze was the only one with:
FAQPage schema with 10 Q&As answering real enterprise buyer questions — such as “How is Muze different from a Software House?” and “Does Muze do Revenue Sharing?” — AI search reads this directly and uses it to answer conversational queries
ProfessionalService schema with a serviceType array of 13 entries — explicitly stating what Muze does: “Streaming & OTT Platform Development”, “FinTech & Trading Platform”, “E-Commerce & Omnichannel” — AI parsers can build entity associations without having to infer from prose
meta robots explicitly allowing rich snippets: max-image-preview:large, max-snippet:-1, max-video-preview:-1 — the only one in the competitive set doing this
Competitors:
- Seven Peaks (ranked 2nd overall): No JSON-LD at all — great content, but AI parsers must infer everything from prose
- Appman: Only default Yoast-generated schema
- Sertis: Only
WebSiteschema — minimum possible
6. AI Search Gap Analysis — A Methodology Built from Scratch
One of the areas where Claude Code contributed most was systematic analysis of how well the existing website covered real buyer queries.
The process:
Step 1: Compiled 12 real buyer queries that potential clients use when searching for an enterprise tech partner in Thailand
Step 2: Mapped each query to existing content — identifying which queries were well covered, which were thin, and which had nothing
Step 3: Found the core problem: content was organised by client name but buyers search by capability — “OTT platform development Thailand” doesn’t match “CH3+” in HTML
Step 4: Fixed i18n strings first — changed Success Stories group labels to use proper buyer language, e.g. “Enterprise Custom Tech” → “Enterprise Custom Software Development”, and added vertical keywords to card descriptions
Step 5: Mapped TechCut articles still needed — FinTech cross-story, Enterprise Custom Software, Strategic Tech Partner positioning
Claude Code handled the analysis, proposed solutions, and executed code changes. Deciding which queries matter and which framing is accurate was human.
7. Human as Source of Truth — Always
At one point during the build, Claude Code wrote content claiming Muze had built a recommendation engine for CH3+ using collaborative filtering.
That was not accurate.
The Muze team corrected it immediately because they knew the project reality better than the AI. This is the clearest example of why human judgment matters: AI can generate narratives that sound entirely plausible — but accuracy comes from the person who actually worked on the project.
The Real Formula for “AI-Built Website That Scores 100”
Human: KPIs + Architecture decisions + Quality gate
AI: Execution + Iteration + Analysis
Not: prompt AI and wait But: Human defines “good” → AI builds → measure → Human judges → AI fixes → repeat
The speed from AI comes from executing iterations faster — not from removing the human from the loop.
Measurable Results
- Lighthouse Desktop: Performance 100 / Accessibility 95 / Best Practices 100 / SEO 100
- LCP: 0.6s (excellent benchmark is ≤ 1.2s)
- Page weight: 66KB (competitors: 174KB–1.6MB)
- Structured data: 11 schema types including FAQPage + ProfessionalService — ahead of all competitors audited
- AI Search Coverage: 9/12 defined buyer queries now covered
This article was drawn from the actual build process of muze.co.th — every insight comes from real iterations, not theory.